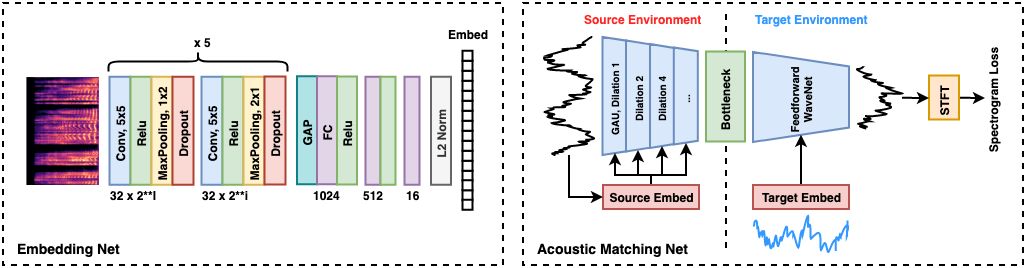
Acoustic matching aims to transform audio recordings made in one acoustic environment to sound as if recorded in a different environment, based on reference recordings made in the target environment. This paper introduces a deep learning solution of two parts to the acoustic matching problem. First, we characterize the acoustic environments by mapping recordings into a low-dimensional embedding that is invariant to speech content and speaker identity. Next, a waveform-to-waveform neural network conditioned on this embedding learns to transform an input waveform to match the acoustic qualities encoded in the target embedding. Listening tests on both simulated and real environments show that the proposed approach improves on state-of-the-art baseline methods.