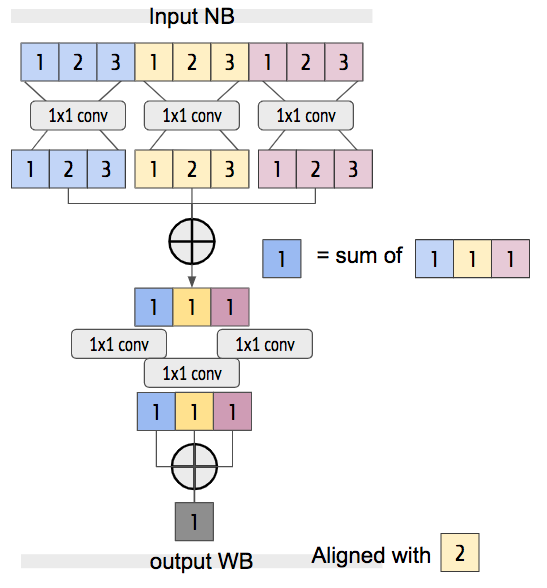
We introduce a perceptually motivated approach to bandwidth expansion for speech. Our method pairs a new 3-way split variant of the FFTNet neural vocoder structure with a perceptual loss function, combining objectives from both the time and frequency domains. Mean opinion score tests show that it outperforms baseline methods from both domains, even for extreme bandwidth expansion. This page contains the audio clips used in the MOS test described in Section 4 of the paper.